The Quest for the Next Transformer
A first-principles exploration of sequence modeling and what might come next.
The transformer architecture has dominated NLP for seven years now. That's a long time in deep learning. CNNs had their run in vision. RNNs had theirs in sequences. Transformers seem to be having a longer one, but nothing lasts forever.
I've been asking myself: what would it take to build something better? Not incrementally better, but fundamentally different. This post is my attempt to work through that question from first principles.
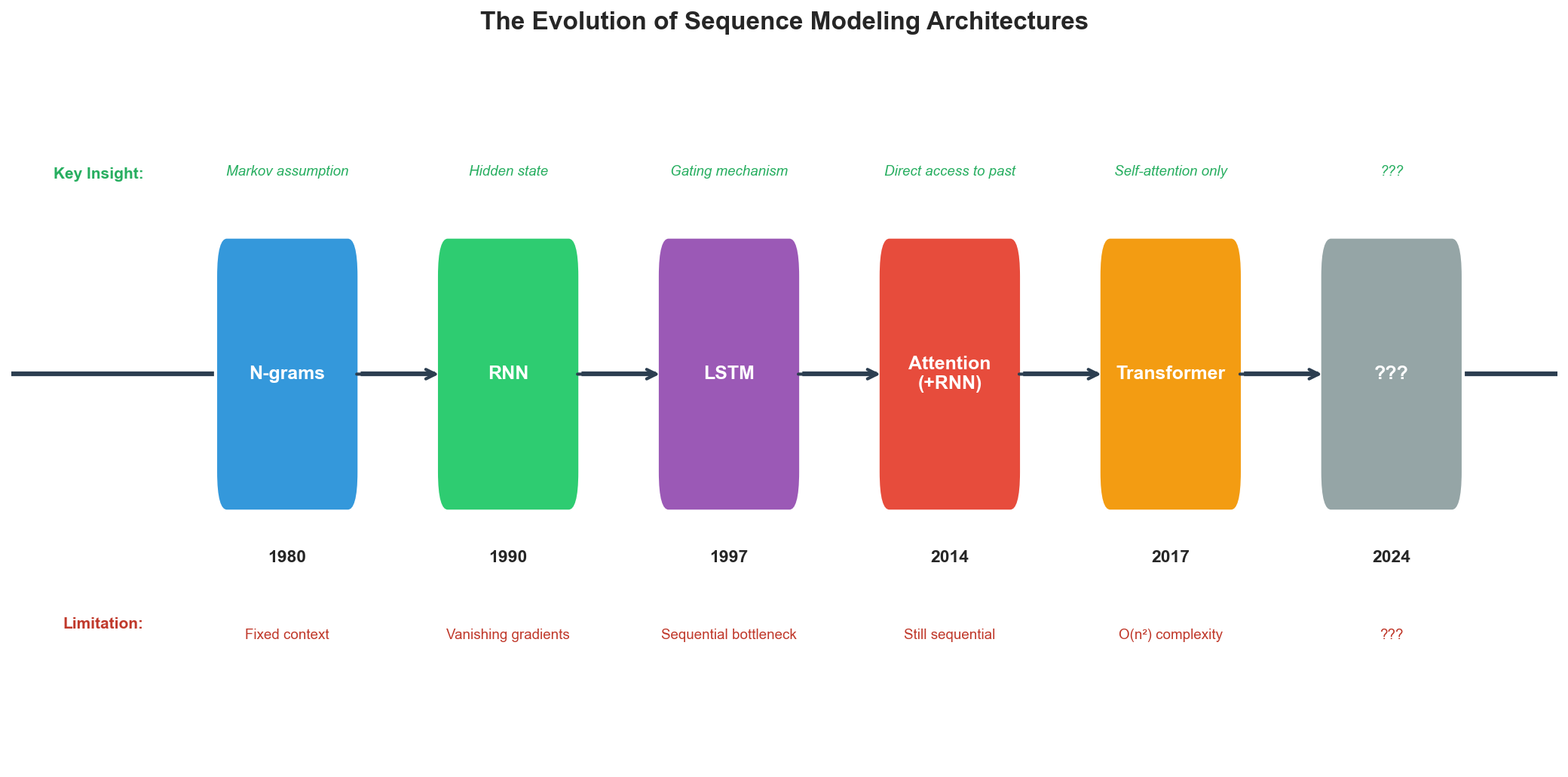
The Problem We're Solving
Text prediction seems simple. Given a sequence of tokens, predict the next one. But the computational requirements are extreme. Language has structure at multiple scales: characters, words, phrases, sentences, paragraphs, documents. Dependencies can span thousands of tokens. The vocabulary is large. The distribution is heavy-tailed.
The core challenge is this: how do you efficiently model relationships between all positions in a sequence? RNNs process sequentially, compressing everything into a fixed-size hidden state. That creates a bottleneck, and long-range dependencies get lost. Transformers solve this with attention: every position can directly access every other position. But that costs O(n²) computation.
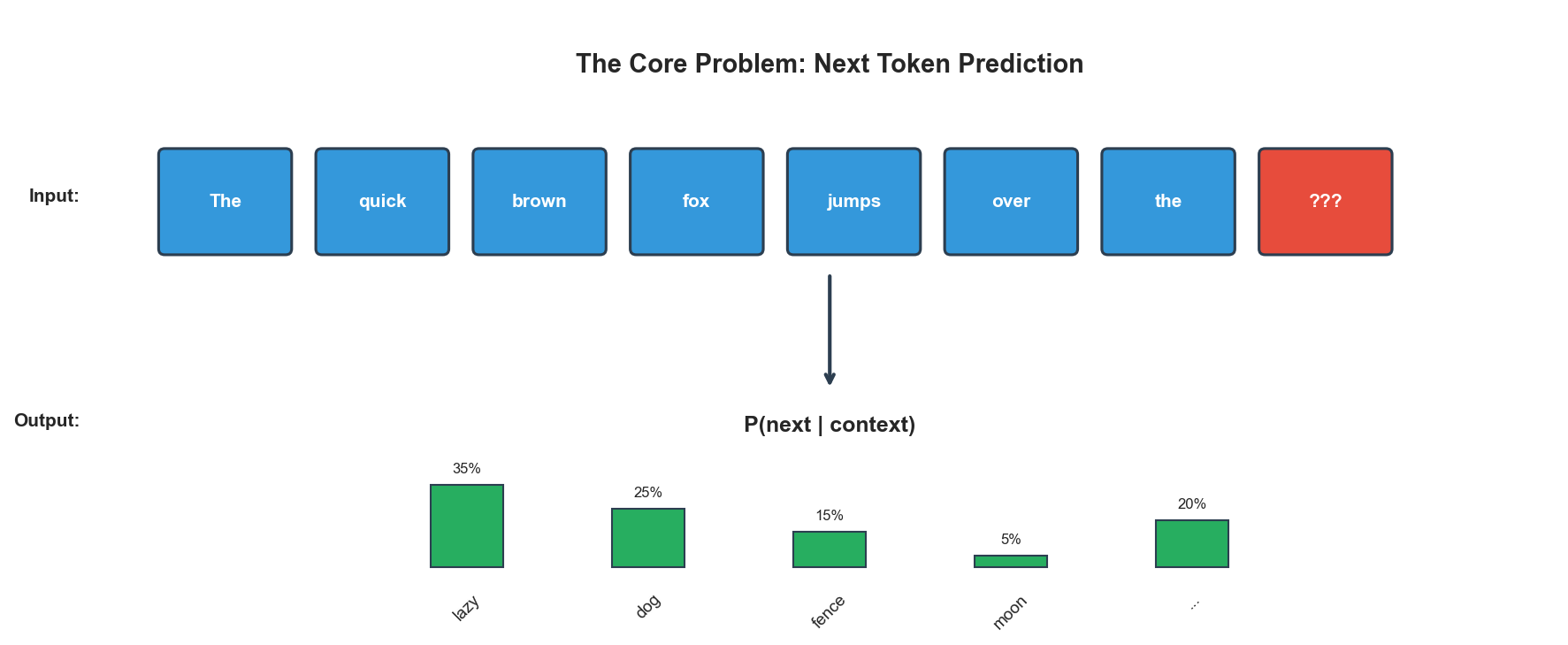
O(n²) is expensive. For a 100K token context, that's 10 billion attention computations per layer. And modern models have dozens of layers. The compute bill adds up fast.
What Makes Transformers Work
Before trying to replace transformers, it's worth understanding why they work so well. Several things stand out.
First, attention is content-based routing. Each token decides what to attend to based on its content, not its position. This lets the model learn flexible patterns. The same word can attend differently depending on context.
Second, the architecture parallelizes beautifully. Unlike RNNs, every position can be processed simultaneously. This maps perfectly to GPU hardware. Training speed is a huge practical advantage.
Third, residual connections and layer normalization make deep networks trainable. You can stack 100+ layers without gradient problems. Depth seems to matter for language understanding.
Fourth, the inductive biases are minimal. Transformers don't assume much about the structure of language. They learn it from data. This generality is both a strength and a weakness. They need massive amounts of data to learn what could be built in.
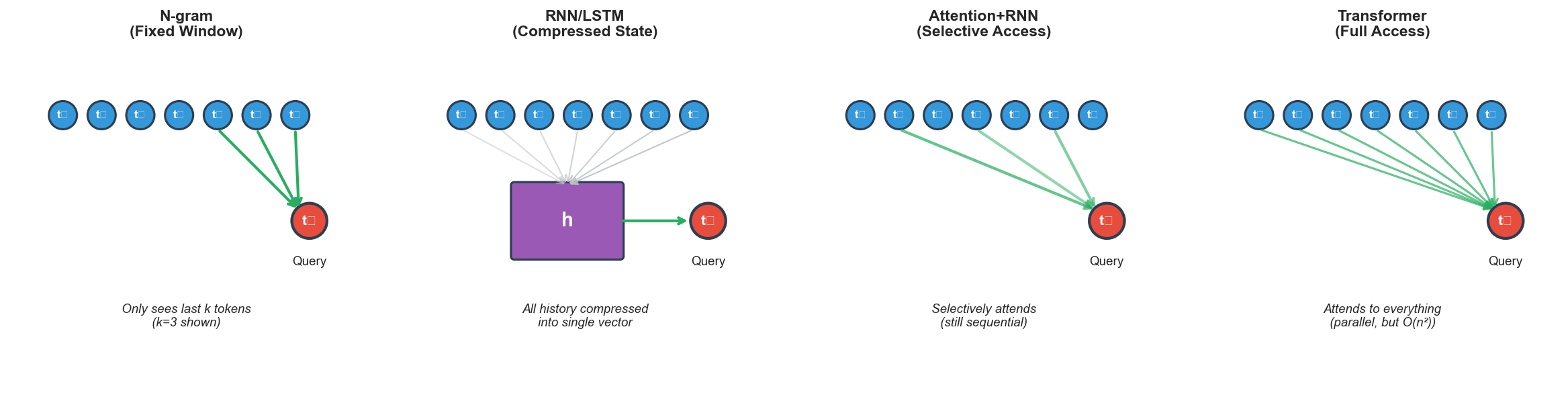
Transformer Limitations
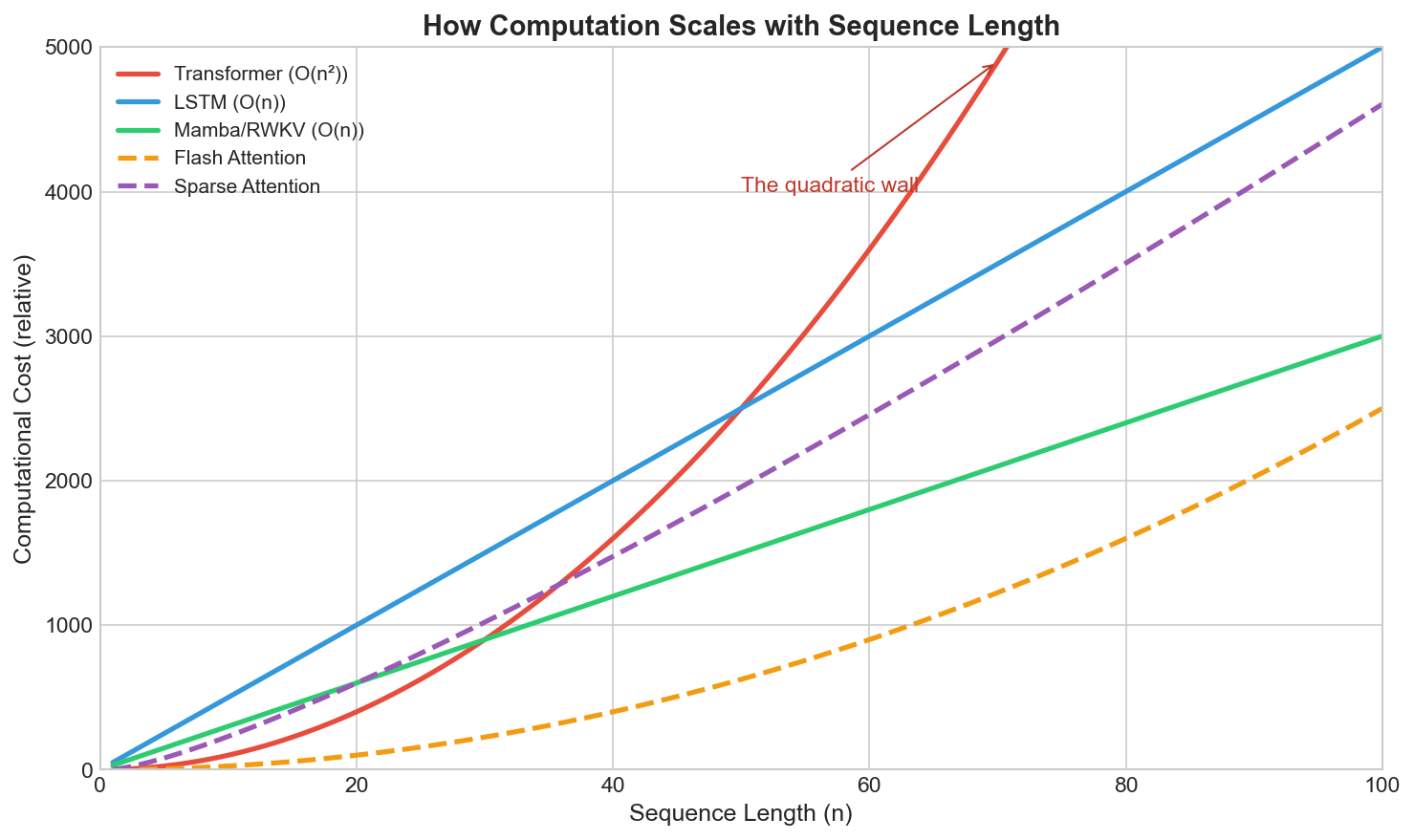
The O(n²) complexity is the obvious problem. Long contexts are expensive. There are workarounds like sparse attention, sliding windows, and memory compression, but they're patches, not solutions.
Less obvious is the efficiency problem. Transformers use the same computation for every token. Easy tokens get as much compute as hard ones. The word "the" gets as much attention as a technical term that requires reasoning. This is wasteful.
The inductive bias problem cuts both ways. Transformers don't build in the hierarchical structure of language. They have to learn that sentences contain phrases contain words. With enough data this works, but it's inefficient. A child learns language with orders of magnitude less data.
There's also the memory problem. Transformers have no persistent state across sequences. Every context window starts fresh. There's no way to accumulate knowledge over a conversation without re-reading everything.
The State of Alternatives
Several research directions are trying to address these limitations.
State Space Models (Mamba, S4, etc.) replace attention with learned linear recurrences. Complexity is O(n) instead of O(n²). They're competitive with transformers on some benchmarks, especially for long sequences. The main question is whether linear dynamics can capture the same patterns as attention. Early results are promising but not conclusive.
Linear Attention variants try to get attention-like behavior without the quadratic cost. The trick is to avoid materializing the full n×n attention matrix. Various approximations exist: random features, low-rank factorization, sparse patterns. None have matched full attention quality, but the gap is narrowing.
Retrieval-Augmented Models separate memory from computation. Instead of attending to everything in context, retrieve relevant chunks from an external store. This decouples context length from compute cost. The challenge is making retrieval differentiable and accurate.
Mixture of Experts reduces computation by routing tokens to specialized sub-networks. Not every parameter activates for every token. This addresses the uniform compute problem but doesn't fundamentally change the attention mechanism.
Looking to Biology
The brain processes language on about 20 watts. Modern LLMs require megawatts. That's a gap worth understanding.
Several brain mechanisms seem relevant. Sparse coding: only 1% of neurons are active at any time. Predictive coding: higher areas predict lower areas, and only prediction errors propagate. Hierarchical processing: different regions operate at different timescales, matching the hierarchical structure of language.
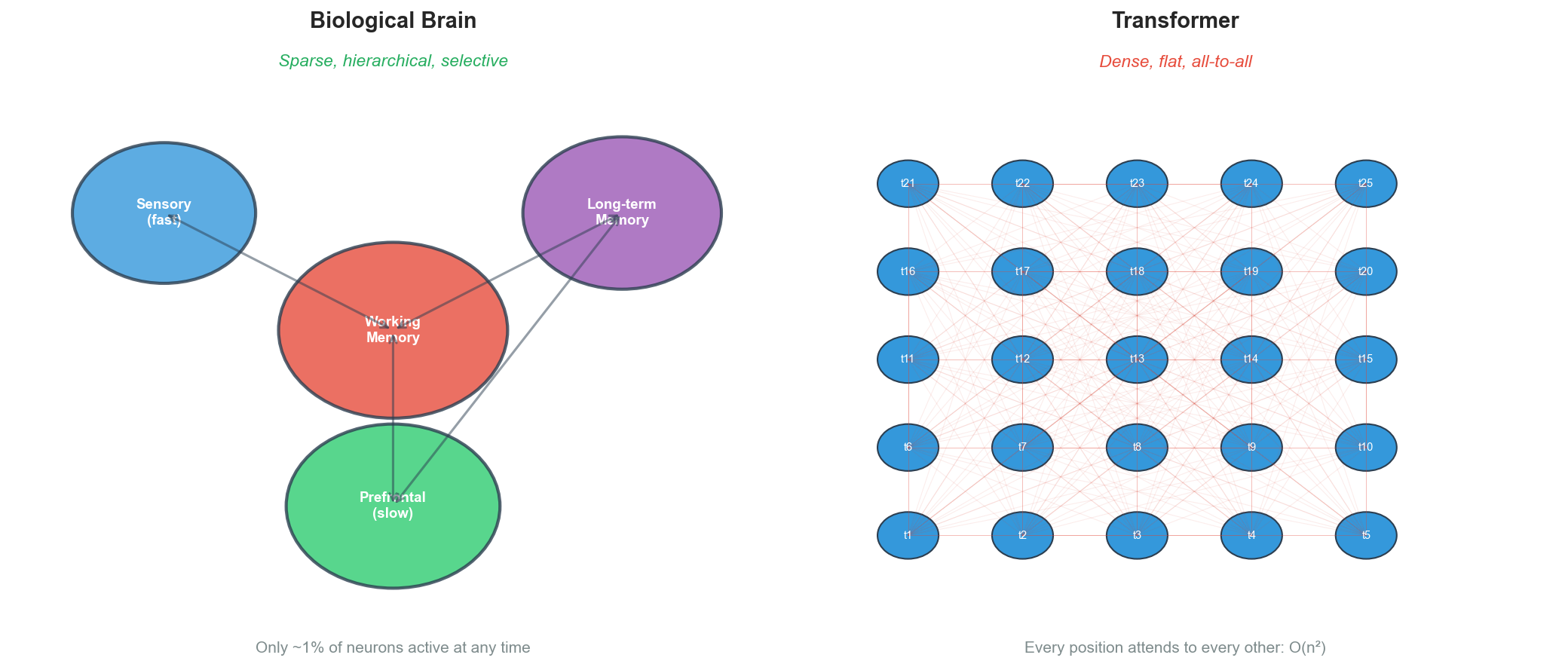
The question is whether these mechanisms can be translated into practical algorithms. "Biologically plausible" doesn't mean "computationally useful." The brain evolved for survival, not for next-token prediction. But the efficiency gap suggests we might be missing something fundamental.
What Would a Successor Need?
Based on this analysis, I think a transformer successor would need several properties.
Sub-quadratic complexity. O(n²) doesn't scale. Any successor needs to be O(n log n) or better while maintaining expressiveness.
Adaptive computation. Not all tokens need equal compute. Easy predictions should be cheap. Hard ones should be able to recruit more resources.
Hierarchical structure. Language is hierarchical. The architecture should reflect this, with different components operating at different timescales and levels of abstraction.
Persistent memory. The ability to accumulate knowledge across contexts without re-reading everything. Some form of external or compressed memory.
GPU-friendly computation. This is pragmatic but essential. Any architecture that doesn't parallelize well won't get the engineering investment needed to scale.
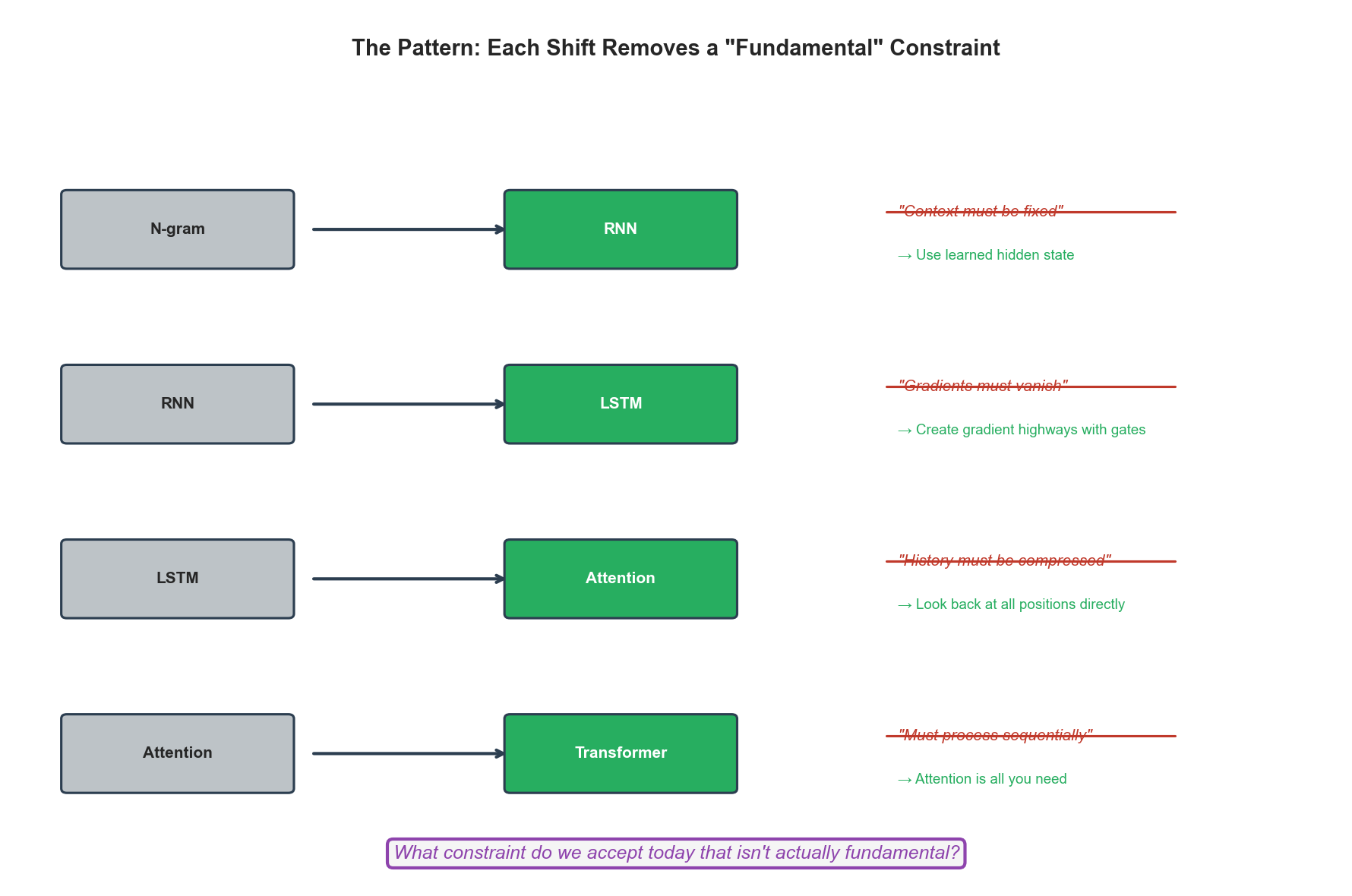
A Possible Direction
One direction I find promising combines several ideas: hierarchical structure with different timescales, predictive coding where only errors propagate, sparse attention for fine-grained modeling, and skip connections to preserve information across the hierarchy.
The intuition is this: lower levels of the hierarchy process fast, capturing local patterns. Higher levels process slowly, capturing document-level context. Each level predicts the level below. When predictions are correct, computation is minimal. When predictions fail, errors propagate and trigger updates.
I've implemented a prototype of this idea. The results are instructive. It doesn't work in pure form. The information bottleneck is too severe. But with augmentations (local attention, skip connections), performance improves substantially. The direction seems worth pursuing.
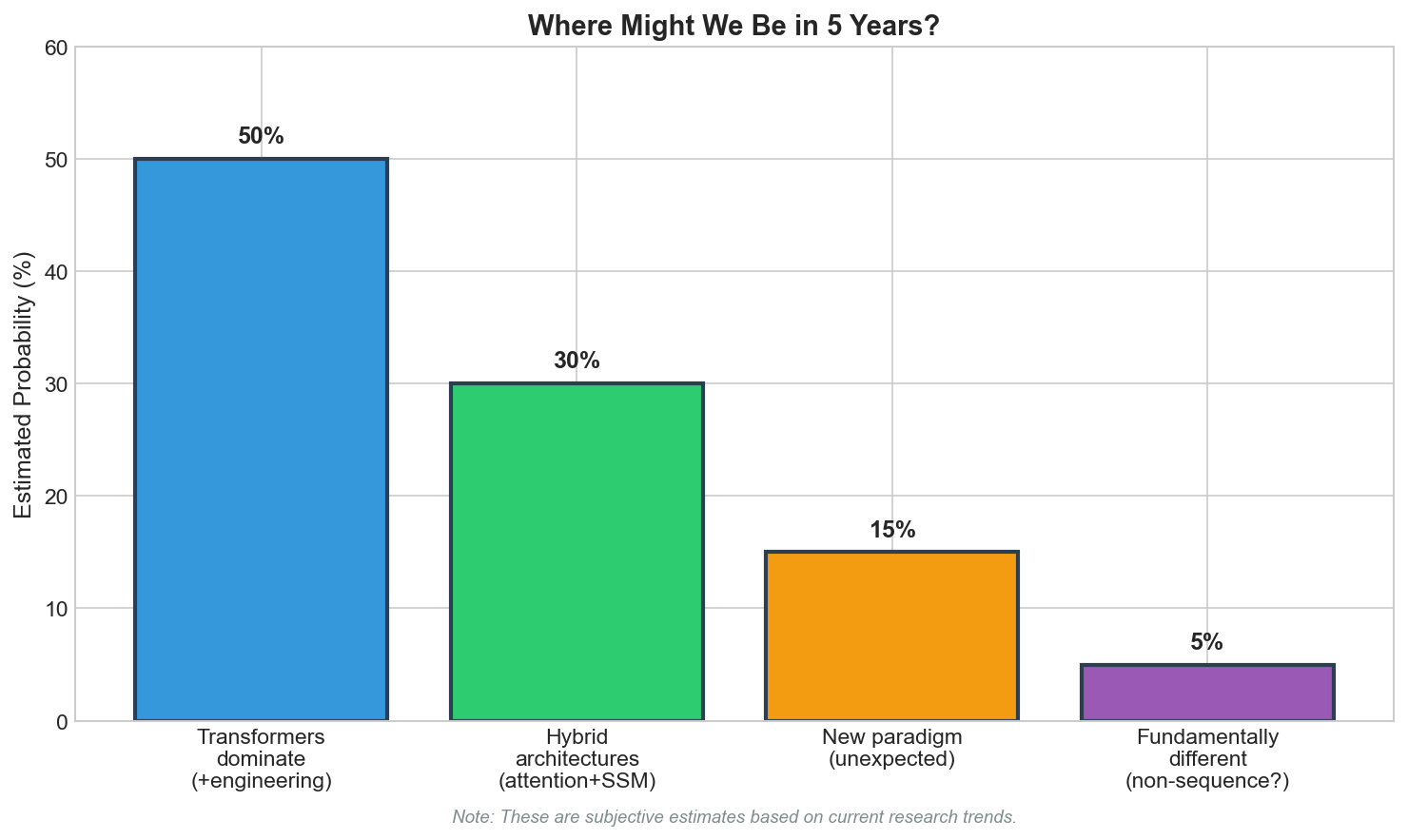
The Honest Conclusion
Can we do better than transformers? Almost certainly yes, eventually. The question is when, and whether "better" means "fundamentally different" or "cleverly augmented."
The pessimistic view: transformers are like convolutions for vision. Not optimal, but good enough that improvements are incremental. The architecture will evolve (sparse attention, mixture of experts, etc.) but the core ideas persist.
The optimistic view: we're at the beginning of understanding sequence modeling. The brain proves that much more efficient solutions exist. Someone will find the right combination of ideas, and it will be as discontinuous as the transition from RNNs to transformers.
My own view: the answer is probably somewhere in between. Pure alternatives haven't matched transformers, but hybrid approaches are promising. The next breakthrough might not be a single architecture but a combination of mechanisms: hierarchical structure, sparse computation, predictive coding, and retrieval augmentation, assembled in a way we haven't figured out yet.
The search continues. And that's what makes this field exciting.